美团LongCat团队正式发布并开源了LongCat-Video视频生成模型,该模型在文生、图生视频基础任务上达到了开源最先进水平,并依托原生视频续写任务预训练,实现了分钟级长视频的连贯生成。这一模型在保障跨帧时序一致性与物理运动合理性的同时,展现了在长视频生成领域的显著优势。
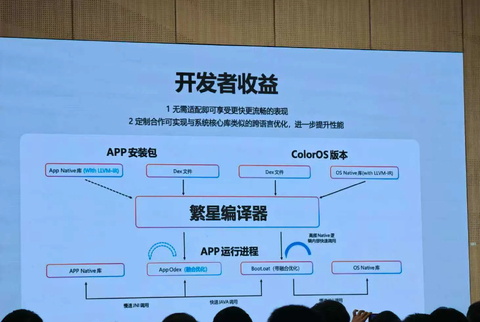
据介绍,“世界模型”被视为通往下一代智能的核心引擎,它能够让AI真正理解、预测甚至重构真实世界。而视频生成模型,则有望成为构建这一世界模型的关键路径。LongCat-Video作为基于Diffusion Transformer架构的多功能统一视频生成基座,通过创新的“条件帧数量”方式实现了任务区分,无需额外模型适配即可原生支持文生视频、图生视频以及视频续写三大核心任务。
在文生视频方面,LongCat-Video能够生成720p、30fps的高清视频,精准解析文本中的物体、人物、场景、风格等细节指令,其语义理解与视觉呈现能力达到了开源最先进水平。在图生视频方面,该模型能够严格保留参考图像的主体属性、背景关系与整体风格,动态过程符合物理规律,支持多种类型输入,内容一致性与动态自然度表现优异。
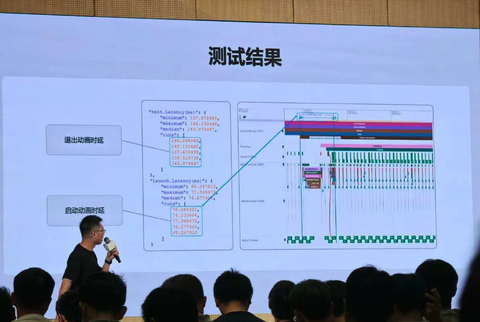
尤为突出的是,LongCat-Video的视频续写能力,可基于多帧条件帧续接视频内容,为长视频生成提供原生技术支撑。依托视频续写任务预训练、Block-Causual Attention机制和GRPO后训练,该模型能够稳定输出5分钟级别的长视频,且质量无损,达到了行业顶尖水平。 | 


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜